Are you High Mix and Low Volume? Do you have poor forecasts? Predictive analytics can still help – with a few tweaks!
Introduction:

The authors were faced with a mounting problem: Sales forecasts were continuing to deteriorate and Corporate was mandating a traditional application of Sales & Operational Planning (S&OP). This application relied on forecasts and static data. Static data is sufficient where forecasts and run-rates are consistent, though that is simply not the case in the Business Unit the authors currently reside. Working with short product life cycles and high demand volatility, clean static data alone will not produce an effective S&OP. Thus the authors began experimenting with a number of analysis tools to assist with improving the S&OP input. The mission was to find a stable way to bias the data so that random variability could be kept in check while allowing our recent history to point us in the right direction. It was our experience that through the use of predictive analytics to feed our S&OP, we arrived at a far more effective plan for operations management.
Background:
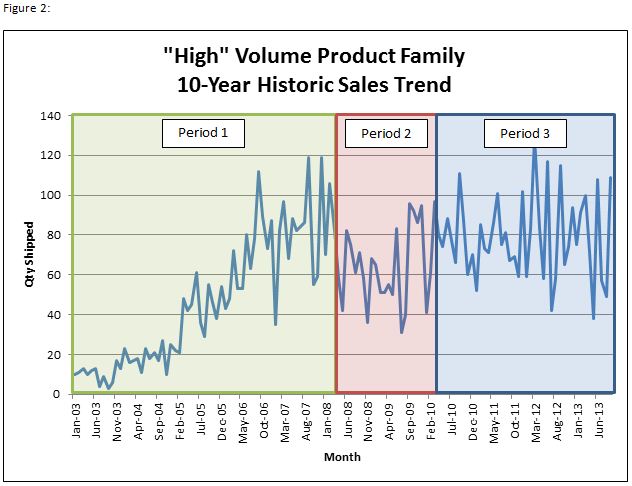
As part of Cobham’s SATCOM division, the Maritime Products facility located in Concord, CA occupies a fairly unique niche along the industry’s operations frontier – a low volume, high mix facility with the largest SKU contributing <5% of annual revenue (Figure 1). At 35 years old, Cobham SATCOM Concord isn’t a young business, however, there is only about 10 years of reliable data on units shipped, product roadmaps, etc. The standard manufacturing lead time for a typical maritime antenna is less than 2 weeks, but less frequent systems are as much as 5 weeks. A critical KPI is on-time delivery (OTD) and this is consistently at or near 100%. OTD is a critical KPI as we ship our products directly to sea-faring vessels in ports all over the world with installation crews standing by. Since these vessels may only be in port for 1-2 days, the antenna must be on-time or the installation crew and antennae delivery need to be re-routed to the next port of call. Missing a delivery can mean a lot more than just down-time for ship communications – it often involves re-positioning antenna installation tools, including cranes, other materials as well as the antennae itself quite quickly in faraway parts of the world. Given the softness of the target market – and also a function of our high OTD – our customers provide virtually no forward visibility of demand. However, our customers still expect extremely high responsiveness. In order to maintain this world-class delivery status, we will build to stock and maintain inventory at several 3PL partners for near-immediate supply to the customer. We are an industry leader with as much as 90% market share or more in certain segments of the market – some segments are 50% or less. Regardless, we have been able to substantially improve forecast and planning accuracy across all market segments through the use of predictive analytics (PA). However, the PA as we have structured it is unique and finally allows us to use PA with a much higher degree of reliability than previous versions.
Why we’re doing this: The units we manufacture represent a significant capital investment for our customers, but forecast accuracy is generally poor. MAPE1 is consistently over 50% for product family forecasts. As a result, our carrying costs for inventory remain high. Industry trends support lower cost targets going forward, but we don’t want to jeopardize our dealer’s ability to deliver antennas to their customers when and where they say they will. Predictive analytics will allow us to purpose with much greater accuracy our world-wide inventory, enabling us to have the right product in the right place at the right time while hitting our cost targets. Whereas PA is usually best utilized in a Low Mix-High Volume environment, we are attempting to use it in a High Mix-Low Volume environment, which presents a certain degree of risk. However, we feel that a better understanding of how to bias the data inputs allows for a consistent improvement in forecast accuracy. Our models shown below will demonstrate that.
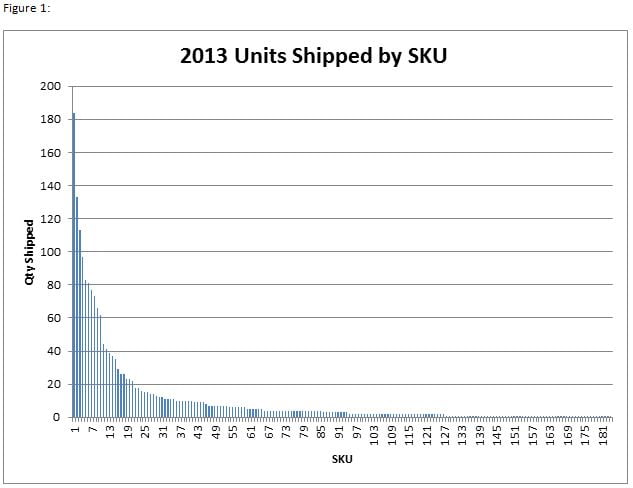
Method: As mentioned before, we only have about 10 years of suitable historical data from which to build any kind of forecasting model. Looking at the graphical representation of the 10-year sales data for one of our higher volume product lines, we can see 3 distinct periods of growth, decline and plateau. These periods make inherent sense when looking at the standard life cycle of our products (Figure 2).
Period 1. Upon introduction to the marketplace we see an extended period of steady growth as more global customers adopt the new product.
Period 2. As the marketplace reaches saturation and viable competitors find ways to lower the barrier to entry, we see a brief period of severe demand fluctuation (which also coincides with the global recession at the time).
Period 3. The market recovers and we see a sustained level of demand which while highly variable shows signs of being predictable.
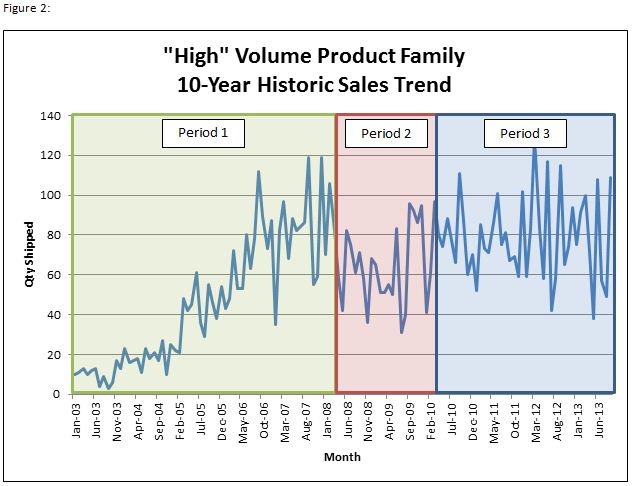
For our purposes, it is this last period of sustained demand that we want to use to develop our model – this ensures that the latest trends for the data are captured and also that the model won’t be adversely effected by earlier product life cycle trends. With that approach we began regression modeling on our historical shipments from the same higher volume product line for the May-10 to Sep -13 time period (Figure 3).
Linear | Dummy | |
| MAPE | 24% | 15% |
| MAD/Mean | 22% | 13% |
As you can see from the historical data, the number of units shipped fluctuates drastically month-to-month. A simple linear regression yields a MAPE of 24%, meaning on average we’ll have 24% error in our predictions for quantity shipped using this model. We use MAPE as a forecast accuracy metric, because it is an industry standard and intuitively understandable. However, because our business has such intermittent demand, a volume-weighted metric is more appropriate and thus we use MAD/Mean Ratio2 as an alternative. Using these measurements to fine-tune our model, it’s now worth attempting to account for the demand variability by inserting monthly trends into our regression. We know from experience that a lot of our business is seasonal, with common monthly trends (i.e. slow annual starts with upticks in demand during the last month of each quarter). With this knowledge we can create a model using dummy variables3 to account for the month-to-month variance in our units shipped. Not only does this model visually seem to ‘fit’ our historical data better, but it also improves upon our previous forecast accuracy measurements. At this point it’s worth comparing the model to our previous sales forecast method, which is based mostly on sales rep intel as well as confirmed contracts for the future (Figure 4).
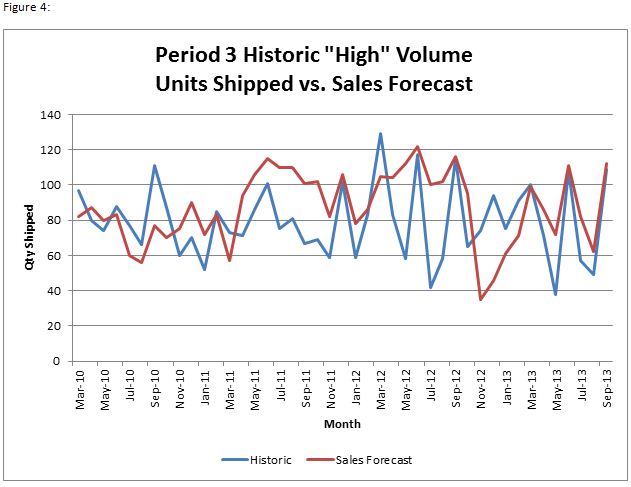
Sales Forecast | |
| MAPE | 30% |
| MAD/Mean | 26% |
It would appear that our models offer a significant improvement over our previous sales forecast – both MAPE and the MAD/Mean Ratio have improved and now we can limit the amount of guesswork required for our forecast predictions. This is all good news, but it’s not really fair to compare the sales forecast against historical data while the regression model has the benefit of being based off the historical data it’s being compared against. Since the sales forecast is forward-looking and gains no benefit from hindsight while the PA model is built off that hindsight, one more regression is required in order to fairly compare both methods. In order to do this, we will base the regression model off only Mar-10 to Dec-12 data, then measure forecast accuracy against actual 2013 units shipped and compare against the 2013 sales forecast (Figure 5).
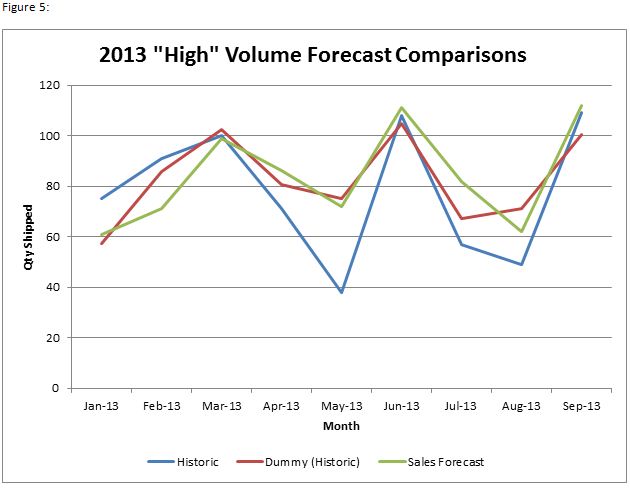
Dummy | Sales Forecast | |
| MAPE | 24% | 25% |
| MAD/Mean | 17% | 18% |
Success! We now have a robust forecast model that improves upon our previous forecasting method while also incorporating historical data trends. As time goes by, our model will continue to dial-in as further observations contribute to the forecast. That is not to say that the old method of forecasting should be completely abandoned. With such low volumes, it’s essential to be able to predict when we may have shipments that can be considered outliers (i.e. outside the 95% confidence interval or beyond a specified number of standard deviations from the expected value). Sales reps who maintain good relationships with their customers will be able to provide certain intangible information that the model simply cannot account for (for example, when a big order comes in or when an order is pushed out to another month).
The whole point of generating this ‘clean’ data for our S&OP process is so that we can anticipate our capacity restraints while limiting our inventory carrying costs. Looking at the potential cost of overage/underage4, allows us to make better decisions about how many actual units to build. When looking at our 2014 forecast projections, we can see that there are significant differences between what our model tells us and what sales is forecasting. Using a standard normal distribution we can determine the probability that we attain our sales forecast. Sales may know something our model can’t tell us, but in those cases where the probability is sufficiently low, it’s worth looking at what costs we stand to absorb as a result of building too many/too few units (Table 1 & Figure 6).
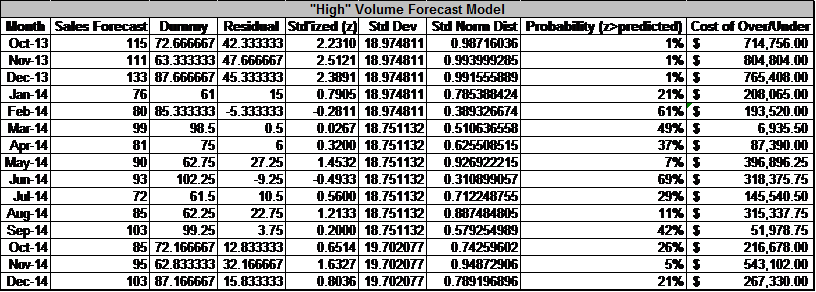
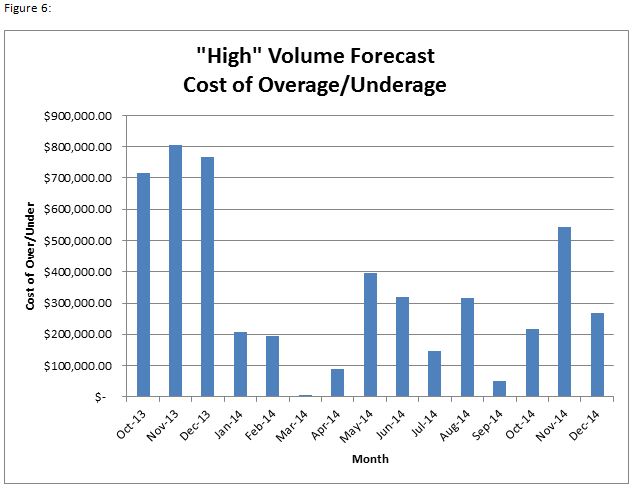
Using this data, we can make decisions about when we want to go with the sales forecast and when it may be most prudent to dial back/ramp up operations based on what our model tells us. For example, In the case of Oct-13 through Dec-13, we have an abnormally large contract which creates a great discrepancy between our regression model and the sales forecast. In this case we’ll go with the sales forecast because the demand information comes directly from the customer (these months will be considered outliers as these contracts rarely happen and exist well outside our historic trends). On the flipside, Nov-14 is showing a large residual with a low probability of us achieving our sales forecast while potentially incurring up to $550,000 in excess cost. Unless Sales knows of a large contract or something else concrete, it will be to our advantage to tell S&OP to plan for fewer systems than the sales forecast indicates.
Conclusion:
We have been able to improve our forecast accuracy by 50% in the example above (and even higher on other product lines) by simply biasing the forecast data used in S&OP with the dummy regression model above. This is especially important when looking at the associated costs of building too much of a certain product or the loss or delay of revenue by not building enough inventory. We have experimented with several different models to find the one that best fit our manufacturing environment. You may need to do the same as your results may vary. While there is no perfect regression model for every environment, experimentation will lead to a solution that should improve your forecast accuracy when forecast accuracy is an impediment to S&OP usefulness. In a high-mix, low volume environment, the effects this can have on a business are significant. We have decreased inventory, improved responsiveness to our customers and maintain a consistent 100% OTD.
[1] Mean Absolute Percentage Error is an industry standard metric used for the measurement of forecast accuracy
[2] Mean Absolute Deviation-to-Mean Ratio is an alternative metric used for the measurement of forecast accuracy which is volume-weighted to account for intermittent demand
[3] An artificially constructed variable that takes on the values of zero and one only. Used to quantify non-numerical qualities or categories. When included in a regression, effectively allows the constant to change depending on the value of the dummy variable
[4] A key component of the classic Newsvendor Model, CO and CU are equivalent to the cost of building one more or one fewer unit than what you would have built had you known demand
About the Authors:
 PAUL MORAES ǀ Mr. Moraes is Director of Operations at Cobham SATCOM Maritime Products, a British aerospace firm headquartered in Wimborne Minster, England, UK. He has spent over 20 years in high tech companies, mostly in Silicon Valley. His education includes business from the University of San Francisco, including a Master Certification in Supply Chain Management and Six Sigma and APICS certification. Connect on LinkedIn
PAUL MORAES ǀ Mr. Moraes is Director of Operations at Cobham SATCOM Maritime Products, a British aerospace firm headquartered in Wimborne Minster, England, UK. He has spent over 20 years in high tech companies, mostly in Silicon Valley. His education includes business from the University of San Francisco, including a Master Certification in Supply Chain Management and Six Sigma and APICS certification. Connect on LinkedIn
WHITNEY SAGAN ǀ Mr. Sagan is Operations Manager at Cobham SATCOM Maritime Products,  a British aerospace firm headquartered in Wimborne Minster, England, UK. Graduating from Northwestern University’s McCormick School of Engineering with a BS in Civil Engineering, Whitney pursued his education further by achieving his MBA – with a focus in Operations – from Northwestern’s Kellogg School of Management. Whitney currently spearheads Cobham’s Excellence in Delivery (EiD) program at their Concord, CA facility. Connect on LinkedIn
a British aerospace firm headquartered in Wimborne Minster, England, UK. Graduating from Northwestern University’s McCormick School of Engineering with a BS in Civil Engineering, Whitney pursued his education further by achieving his MBA – with a focus in Operations – from Northwestern’s Kellogg School of Management. Whitney currently spearheads Cobham’s Excellence in Delivery (EiD) program at their Concord, CA facility. Connect on LinkedIn
© Paul Moraes and Whitney Sagan. All rights reserved.



